![]()
![]()
Das Hauptziel des dtec.bw-Projektes »Rechencluster Logistiksimulation SanDstBw« ist die Bereitstellung der simulationsbasierten Analysefähigkeit für Logistikketten mit der Hauptanwendung im Sanitätsdienst der Bundeswehr.
Unser intensiver Einsatz der Computersimulation für die Planung und Durchführung der sanitätsdienstlichen Übungs- und Einsatzlogistik hebt die Analysefähigkeit und damit das Risikomanagement in diesem Bereich auf ein neues Niveau. Durch die Berücksichtigung stochastischer Einflüsse (z. B. Verletzungsmuster, Ausfall von Ressourcen, Wetter etc.) gelangen wir mit Hilfe von Simulationsmodellen zu erheblich besseren Einschätzungen der Planungssituation als mit einfachen Rechenmodellen. Nur mit dieser Methodik ist eine realitätsnahe Kapazitätsplanung möglich. Diese wird benötigt, um einerseits der militärischen Führung und ggf. den Verbündeten die Effektivität der eingesetzten Ressourcen zu verdeutlichen, aber auch um andererseits dem Bundestag die Effizienz – im Sinne einer bestmöglichen Verwendung des veranschlagten Budgets – nachzuweisen. Die Digitalisierung durch Simulationsmodelle hilft nicht nur bei der Planung von Übungen und Einsätzen, sondern auch bei ihrer Durchführung. Durch die Auswertung von What-if-Simulationen kann die militärische Führung vor dem Einsatz zahlreiche Varianten vergleichen und bei Bedarf die Einsatztaktik den Gegebenheiten anpassen, um die Erfolgswahrscheinlichkeit zu erhöhen.
Projektlaufzeit: 01.10.2020 bis 31.12.2026
Damit dies gelingt, sind realitätsnahe Simulationsmodelle nötig, die wir mit echten Patienten- und Prozessdaten kalibrieren. Das höchste Niveau der Analysefähigkeit erhalten wir aber erst durch die Durchführung einer sehr großen Anzahl von Simulationsläufen mit vielen unterschiedlichen Konfigurationen, dem sogenannten Data Farming, also quasi die Erzeugung von Big Data mittels Simulation. Es kommen jedoch wegen der Komplexität der logistischen Simulationsmodelle pro Konfiguration häufig Laufzeiten im Bereich von Minuten oder sogar Stunden zustande. Das führt dann bei Tausenden oder evtl. sogar Millionen von zu untersuchenden Konfigurationen auf normalen Arbeitsplatzrechnern schnell zu Data Farming-Experimenten mit mehreren Wochen Simulationszeit. Die einzige Lösung dafür ist die parallele Simulation möglichst vieler Konfigurationen auf einem dedizierten Rechencluster.
In einem zweiten Schritt werden die beim Data Farming erzeugten Daten als Eingangsdaten für KI-Verfahren, genauer maschinelle Lernverfahren (wie z. B. zur Parametergewinnung neuronaler Netze) genutzt. Die entstehenden trainierten Systeme reflektieren die Information, die in den Simulationsdaten enthalten ist und können so in kompakter Form Planern oder Entscheidern zur Verfügung gestellt werden. Da je nach Lernverfahren für reale Anwendungsfälle enorme Datenmengen verarbeitet werden müssen, führt dies wiederum zu extremen Laufzeiten. Diese Laufzeiten können auf normalen Rechnern Dimensionen annehmen, durch die viele reale Problemstellungen schlicht nicht bearbeitbar sind. Eine Lösung stellt hier Hardware dar, die durch massive Parallelisierung die Lernzeiten auf anwendbare Dimensionen reduziert.
In einem dritten Schritt können sowohl die Originaldaten aus dem Data Farming als auch die mittels Machine Learning generierten Modelle für Data Analytics genutzt werden, um Entscheidungsprozesse bei der Planung und Durchführung von Einsätzen im SanDstBw zu unterstützen. Die ersten beiden Schritte sollen zwar möglichst schnell ablaufen, müssen aber nicht interaktiv mit einem Benutzer, der vor dem Bildschirm auf ein Ergebnis wartet, durchgeführt werden. Im Gegensatz dazu kommt es bei den Data-Analytics-Anwendungen auf sehr kurze Antwortzeiten an. Auch dies erfordert eine entsprechende Hardwareumgebung.
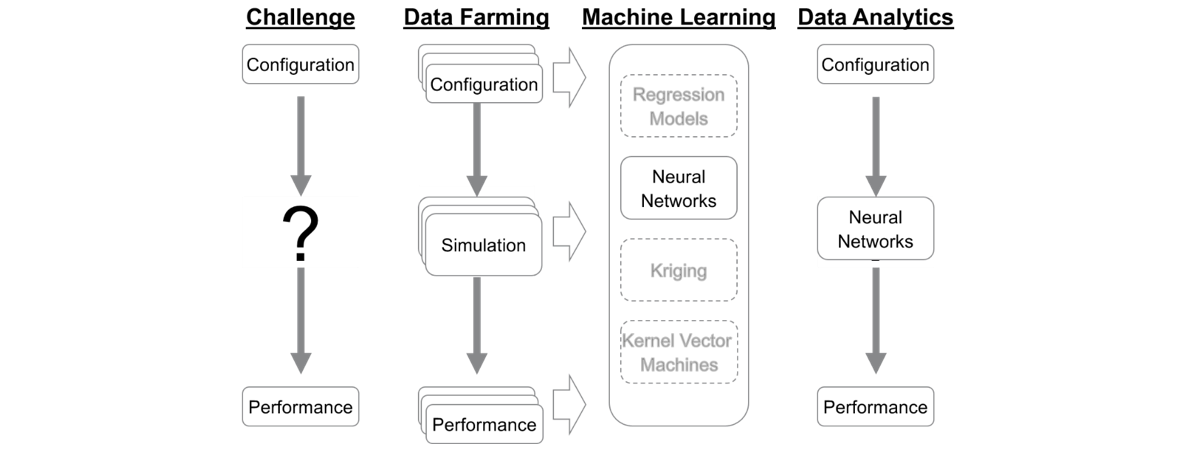
Um die dargestellte Analysefähigkeit durch eine Kombination von Data Farming mit logistischen Simulationsmodellen, Machine Learning und Data Analytics zu ermöglichen, verwenden wir unseren eigenen auf diese Anwendung zugeschnittenen Rechencluster mit der passenden Software.
Militärische Logistikketten müssen heute ein hohes Maß an Performance aufweisen. Daher sind diese Ketten klar auf Effektivitätsziele (Verfügbarkeit, Einsatzbereitschaft, Robustheit) und auf Effizienzziele (Budget, Ausgaben) ausgelegt. Dies spiegelt gemäß obiger Abbildung die Performance wider.
![]()
Prof. Dr. Oliver Rose
Universität der Bundeswehr München
Fakultät für Informatik
Universität der Bundeswehr München
Fakultät Wirtschafts- und Organisationswissenschaften
Beschaffung und Supply Management
Univ.-Prof. Dr. Michael Eßig
Tel.: +49 89 6004-4220
E-Mail: michael.essig@unibw.de
www.unibw.de/beschaffung
Universität der Bundeswehr München
Wirtschafts- und Organisationswissenschaften
Institut für Management marktorientierter Wertschöpfungsketten
PD Dr. Andreas Glas
Tel.: +49 89 6004-4219
Mail: andreas.glas@unibw.de
www.unibw.de/beschaffung


